Google Data Analytics Capstone Project: Empowering Women's Wellness (R)

Understanding consumer behavior is essential for driving business growth in the digital age. This article describes a capstone project from the Google Data Analytics Professional Certificate where we explore a fictional scenario featuring Bellabeat, a high-tech company that creates health-focused smart products for women. The project provides a practical example of applying the data analytics skills learned during the course, using real data from Kaggle to gain valuable insights that can be acted upon.
Bellabeat, founded in 2013 by Urška Sršen and Sando Mur, creates technology that helps women understand their health and habits. Sršen has challenged the marketing analytics team to analyze smart device usage data to shape Bellabeat's marketing strategy for one of its products.
This case study follows the six steps of data analysis as taught in the course: Ask, Prepare, Process, Analyze, Share, and Act. Through this framework, we will answer three guiding questions:
- What are the trends in smart device usage?
- How can these trends apply to Bellabeat customers?
- How can these trends influence Bellabeat's marketing strategy?
Phase 1: Ask
To initialize a data analysis project, it is essential to ask the right questions. This step is crucial because it helps you understand the problem at hand and sets the stage for the investigation. Our current task is to analyze FitBit fitness tracker data from smart devices to uncover insights. Our objective is to use these insights to inform the product and marketing strategy of Bellabeat.
Understanding our stakeholders is equally important as it allows us to align our analysis with their interests and expectations. Here are the key stakeholders for this project:
- Urška Sršen and Sando Mur: As the co-founders, their interest lies in the strategic application of our findings to steer the company's growth.
- Bellabeat Marketing Analytics Team: Our team will drive the analysis, translating data into actionable insights.
- Bellabeat Customers: Insights gained will ideally resonate with current and potential customers' needs and preferences.
- Bellabeat's Marketing Team: They will utilize the insights to shape and implement effective marketing strategies.
- Bellabeat's Product Development Team: Depending on the findings, product adjustments or developments might be needed to align with identified consumer trends.
- Investors in Bellabeat: The insights may influence strategic decisions affecting the company's market position and financial performance, which are of keen interest to investors.
In essence, we are tasked with using smart device usage data to reveal trends and behaviors that can inform Bellabeat's marketing strategy and assist product development. We aim to provide a clear summary of the task, data source descriptions, data manipulation documentation, a summary of our analysis, supporting visualizations, key findings, and high-level content recommendations based on our analysis.
Phase 2: Prepare
In the second phase of our data analysis journey, we need to prepare the data. This means we need to identify the metrics required for our analysis, find the data, and consider security measures. To achieve our goals, we are recommended to use a public dataset called the FitBit Fitness Tracker Data, which is available on Kaggle. This dataset contains personal tracker data from thirty FitBit users, providing minute-level output for physical activity, heart rate, and sleep monitoring. Importantly, it also includes daily activity information such as steps, calories, and intensities.
Our data is stored in CSV files hosted in a GitHub repository.
In terms of credibility and bias in our data, we apply the ROCCC framework (Reliable, Original, Comprehensive, Current, Cited):
- Reliability: The data, collected via Amazon Mechanical Turk, comes from consenting FitBit users, suggesting a reasonable level of reliability. However, it only has 30 respondents.
- Originality: The data appears to be original, derived directly from users' FitBit devices.
- Comprehensiveness: The dataset provides minute-level data on physical activity, heart rate, and sleep monitoring, offering a comprehensive view of users' habits.
- Currency: The data was collected in 2016. While not current, it may still provide useful insights unless recent trends are our primary concern.
- Citation: The dataset has a high usability rating on Kaggle, has been downloaded over 90,000 times, and is acknowledged by Zenodo, attesting to its credibility. However, it comes form a third party which ultimately makes it difficult to verify the data.
The data will aid our analysis by providing a broad range of activity tracking metrics, enabling us to explore fitness and health patterns. Although it has limitations, it is a valuable resource for our this practice project and provides the foundation for the following analysis.
Phase 3: Process
The third phase of our data analysis journey is processing the data. This involves:
- Exploring the data
- Checking for and handling missing values and duplicates
- Transforming data
In this project, we’re going to use R to manipulate the data.
Our data, sourced from FitBit Fitness Tracker Data on Kaggle, consists of four CSV files: daily activity, daily sleep,
hourly activity, and hourly calories data. In our data processing phase, we begin by loading the necessary libraries and
reading in our datasets. We then take a quick look at the structure of each dataset using the head() function.
library(tidyverse)
library(lubridate)
library(dplyr)
library(ggplot2)
library(tidyr)
daily_activity <- read_csv("repos/google-data-analytics-capstone/fitabase_data/daily_activity_data.csv")
daily_sleep <- read_csv("repos/google-data-analytics-capstone/fitabase_data/daily_sleep_data.csv")
hourly_activity <- read_csv("repos/google-data-analytics-capstone/fitabase_data/hourly_intensity_data.csv")
hourly_calories <- read_csv("repos/google-data-analytics-capstone/fitabase_data/hourly_calories_data.csv")
Upon inspection, we find that the data is in wide format, where each row represents a unique combination of user ID and activity date, and each metric (like steps, calories, distance, etc.) is represented as a separate column:
head(daily_activity)
head(daily_sleep)
head(hourly_activity)
head(hourly_calories)

To check the data's integrity, we calculate the number of unique user IDs in each dataset. We also check for missing values and duplicate entries.
# Calculate the number of unique IDs
num_unique_ids_activity <- length(unique(daily_activity$Id))
num_unique_ids_sleep <- length(unique(daily_sleep$Id))
num_unique_ids_hourly_activity <- length(unique(hourly_activity$Id))
num_unique_ids_hourly_calories <- length(unique(hourly_calories$Id))
'daily_activity', 'hourly_activity', and 'hourly_calories' have 33 IDs. 'daily_sleep' has 24 IDs.
# Check for missing values
missing_values_activity <- sapply(daily_activity, function(x) sum(is.na(x)))
missing_values_sleep <- sapply(daily_sleep, function(x) sum(is.na(x)))
missing_values_hourly_activity <- sapply(hourly_activity, function(x) sum(is.na(x)))
missing_values_hourly_calories <- sapply(hourly_calories, function(x) sum(is.na(x)))
There is no missing data.
# Check for duplicate entries
duplicate_entries_activity <- sum(duplicated(daily_activity))
duplicate_entries_sleep <- sum(duplicated(daily_sleep))
duplicate_entries_hourly_activity <- sum(duplicated(hourly_activity))
duplicate_entries_hourly_calories <- sum(duplicated(hourly_calories))
We find 3 duplicate values in 'daily_sleep'.
Removing the duplicates:
# Remove duplicates from the daily sleep data
daily_sleep <- daily_sleep[!duplicated(daily_sleep), ]
In order to merge 'daily_activity' and 'daily_sleep', we first make sure that the date columns in both datasets have the same name, 'ActivityDate', and that they are in datetime format:
# Convert 'ActivityDate' to Date type in daily activity
daily_activity$ActivityDate <- as.Date(daily_activity$ActivityDate, format = "%m/%d/%Y")
# Convert 'SleepDay' to Date type and rename it to 'ActivityDate'
daily_sleep$SleepDay <- as.Date(daily_sleep$SleepDay, format = "%m/%d/%Y %I:%M:%S %p")
names(daily_sleep)[names(daily_sleep) == "SleepDay"] <- "ActivityDate"
We then merge the 'daily_activity' and 'daily_sleep' datasets based on user ID and activity date:
# Perform a left join on 'Id' and 'ActivityDate'
merged_df <- merge(daily_activity, daily_sleep, by = c("Id", "ActivityDate"), all.x = TRUE)
After merging, we create two separate data frames. One contains all data (with a focus on activity data) and another contains only complete sleep data.
# Create a dataframe with all data (will focus on activity data)
activity_data <- merged_df
# Create a dataframe with only complete sleep data
sleep_data <- na.omit(merged_df[, c("TotalSleepRecords", "TotalMinutesAsleep", "TotalTimeInBed")])
We check the first few rows in the new merged dataset and it's types:
head(merged_df)
str(merged_df)

The NA values in the sleep columns are expected as we knew from the previous phase that there were less IDs in the sleep dataset. Thus, when we joined the datasets, only the IDs which existed in both the sleep data and activity data will have values in the columns from the sleep dataset.
Now that the data has been cleaned and organised, it’s ready to be analysed.
Phase 4 and 5: Analyze & Share
The analyze phase is where we take a deep dive into our data, exploring its various aspects and answering the questions
we set out in the ask phase. This is also where the power of R really shines, as it provides a range of functions and
packages that make data analysis efficient. In this case, we're using R and dplyr for data manipulation, ggplot2 for
data visualization, and cor() for correlation analysis.
The Share phase involves creating data visualizations to effectively communicate our high-level insights and
recommendations. I will combine these steps to make the text flow more smoothly, especially since I am utilizing
visualizations in my analysis.
We start by calculating descriptive statistics such as the average daily steps, total minutes asleep, and total time in bed, to get a feel and understanding of the data.
"DESCRIPTIVE STATISTICS"
# Descriptive statistics for average daily steps
activity_data$TotalSteps %>% summary()
# Descriptive statistics for very active minutes
activity_data$VeryActiveMinutes %>% summary()
# Descriptive statistics for fairly active minutes
activity_data$FairlyActiveMinutes %>% summary()
# Descriptive statistics for lightly active minutes
activity_data$LightlyActiveMinutes %>% summary()
# Descriptive statistics for total minutes asleep
sleep_data$TotalMinutesAsleep %>% summary()
# Descriptive statistics for total time in bed
sleep_data$TotalTimeInBed %>% summary()
# Descriptive statistics for average calories burned
activity_data$Calories %>% summary()

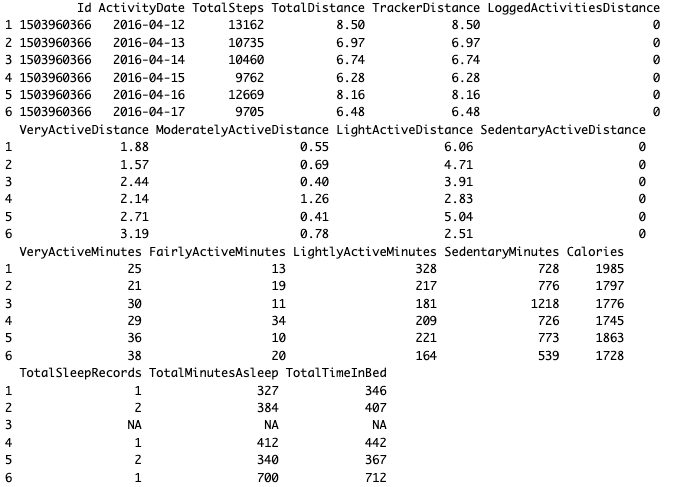
We also check the distributions of total steps and minutes asleep with histograms.
"DISTRIBUTIONS"
"Let's check the distributions of total steps and minutes asleep"
# Histogram of total steps
ggplot(activity_data, aes(x = TotalSteps)) +
geom_histogram(binwidth = 1000, fill = "skyblue", color = "black") +
theme_minimal() +
labs(x = "Total Steps", y = "Count", title = "Histogram of Total Steps")
# Histogram of total minutes asleep
ggplot(sleep_data, aes(x = TotalMinutesAsleep)) +
geom_histogram(bins = 40, fill = "skyblue", color = "black") +
theme_minimal() +
labs(x = "Total Minutes Asleep", y = "Count", title = "Histogram of Total Minutes Asleep")
Next, we will explore the relationships between various variables that I hypothesized could be relevant for the business task. In this article, I will only include a few variables with interesting results. However, I also tested other variables that showed no associations and were left out of this article.
Steps and Calories
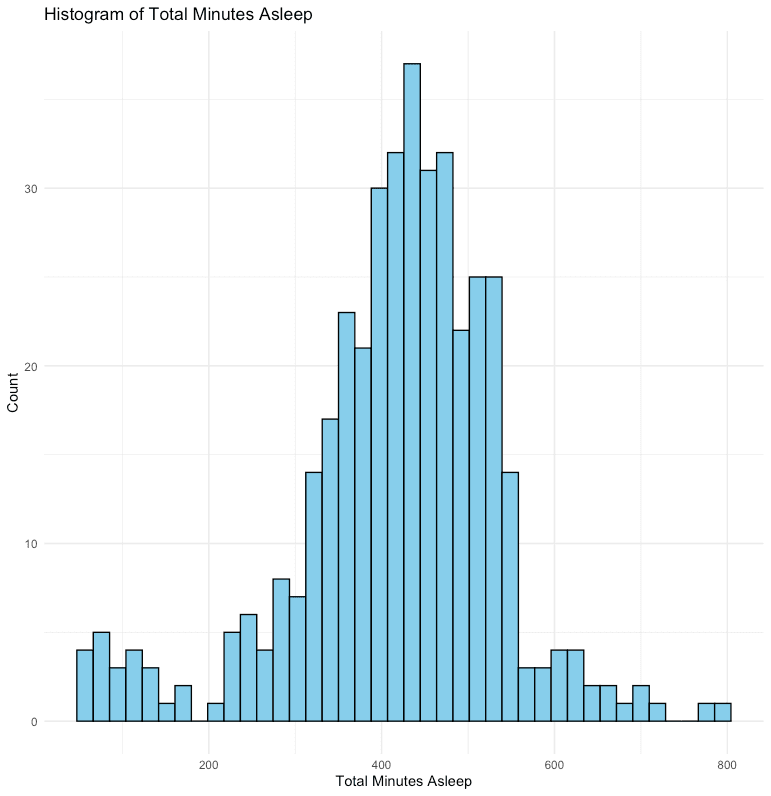
Plotting the number of steps taken and the corresponding calories burned in a scatter plot reveals a clear relationship between the two variables. We also calculated the correlation coefficient between the two variables and found a moderate relationship of 0.59. This relationship is expected as walking burns calories. Therefore, on average, taking more steps should result in burning more calories.
# Scatter plot of total steps vs calories with smoothing line
ggplot(activity_data, aes(x = TotalSteps, y = Calories)) +
geom_point(alpha = 0.5) +
geom_smooth(method = "loess", color = "red", linetype = "dashed") +
theme_minimal() +
labs(x = "Total Steps", y = "Calories", title = "Scatter Plot of Total Steps vs Calories with Smoothing Line")
# Calculate correlation between total steps and calories
correlation_steps_calories <- cor(activity_data$TotalSteps, activity_data$Calories, use = "complete.obs")
print(correlation_steps_calories)
Sedentary Minutes and Sleep
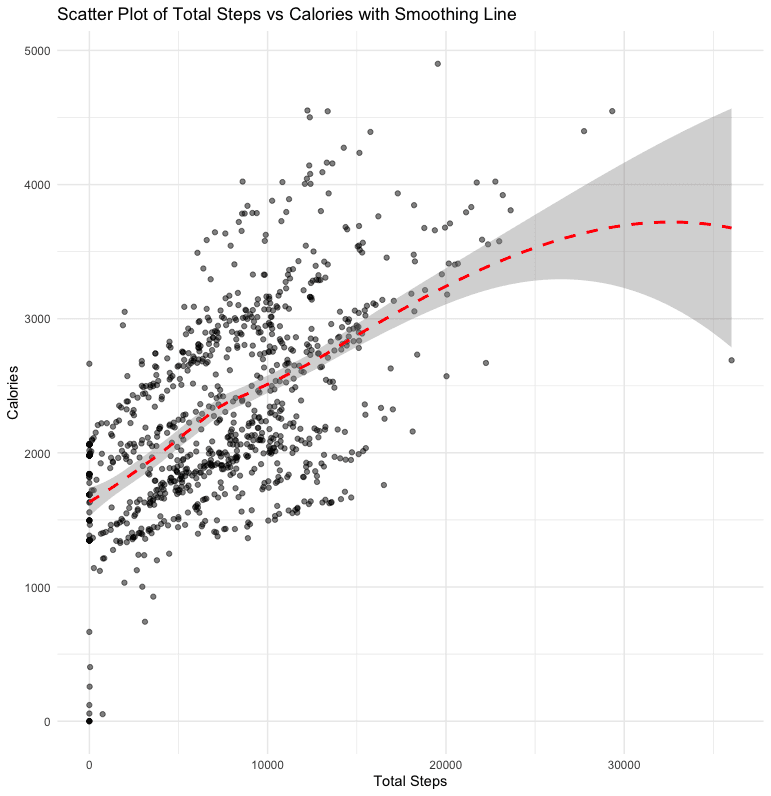
We found a weak but still existing negative relationship between sedentary minutes and minutes of sleep. Looking at the plot, it appears that there is a "normal" range of sedentary minutes (approximately 500-1000) where sleep isn't significantly correlated. However, for more than 1000 sedentary minutes, there is a decrease in the amount of sleep. This suggests that people who spend more time sitting or inactive tend to sleep less. This relationship isn't as clear for those who spend between 500-1000 sedentary minutes, suggesting a possible threshold effect or other confounding factors. We also can’t make any inferences about causation since these are simple correlations.
ggplot(data=merged_df, aes(y=TotalMinutesAsleep, x=SedentaryMinutes)) +
geom_point(color='darkblue') + geom_smooth() +
labs(title="Minutes Asleep vs. Sedentary Minutes")
# Calculate correlation between sedentary minutes and total minutes asleep
correlation_sedentary_sleep <- cor(merged_df$SedentaryMinutes, merged_df$TotalMinutesAsleep, use = "complete.obs")
print(correlation_sedentary_sleep)
Hourly Activity Levels
We find that people are most active between 5 pm to 7 pm. This could be due to various factors, such as work schedules, meal times, or simply personal preferences for evening workouts.
# Group by Hour and calculate mean TotalIntensity
hourly_activity %>%
mutate(Hour = hour(ActivityHour)) %>%
group_by(Hour) %>%
summarise(mean_total_int = mean(TotalIntensity, na.rm = TRUE)) %>%
# Create bar plot
ggplot(aes(x = factor(Hour), y = mean_total_int)) +
geom_col(fill = 'darkblue') +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5)) +
labs(x = "Hour of Day", y = "Average Total Intensity", title = "Average Total Intensity vs. Time")

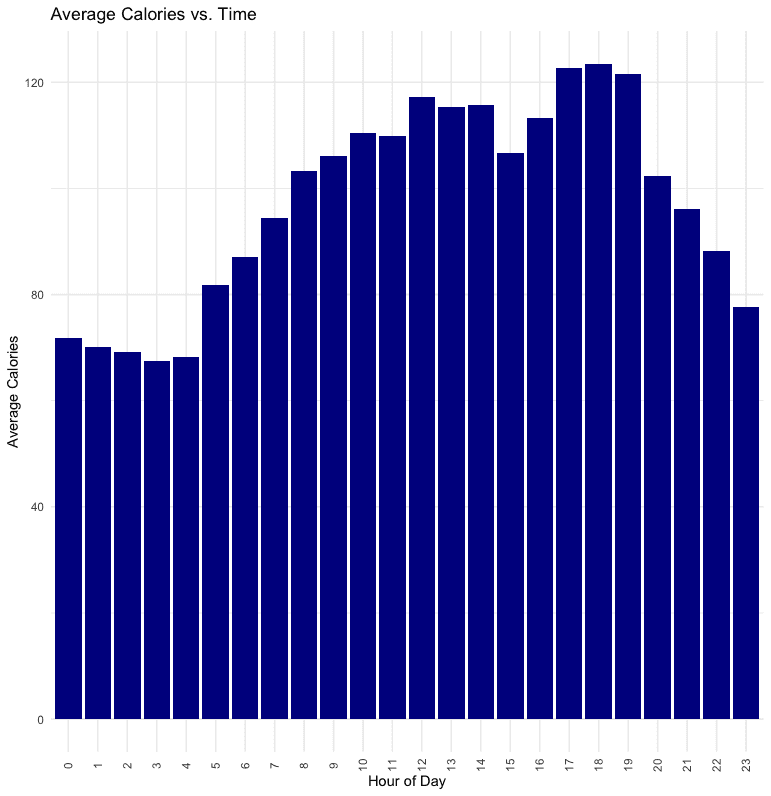
Hourly Calorie Levels
Most calories are burned between 5-7 pm, in line with the intensity levels. However, this distribution is less volatile than that of average intensity.
# Group by Hour and calculate mean Calories
hourly_calories %>%
mutate(Hour = hour(ActivityHour)) %>%
group_by(Hour) %>%
summarise(mean_calories = mean(Calories, na.rm = TRUE)) %>%
# Create bar plot
ggplot(aes(x = factor(Hour), y = mean_calories)) +
geom_col(fill = 'darkblue') +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5)) +
labs(x = "Hour of Day", y = "Average Calories", title = "Average Calories vs. Time")
Phase 6: Act
In the last of the six phases, I'll provide a few recommendations on next steps for how the findings of my analysis can be used to improve Bellabeat's products and marketing strategies.
How could these trends apply to Bellabeat customers?
- Product Development and Features: Recognizing that very active minutes are more common than fairly active ones suggests that customers may prefer more intense workouts. Bellabeat could develop features or partner with workout providers that cater to high-intensity workouts.
- User Engagement: If most activity and calorie burning occurs between 5-7 pm, Bellabeat could tailor notifications and reminders to encourage users to be active during this time. For example, they could send motivational messages or workout suggestions in the late afternoon.
- Sleep Tracking: The negative relationship between sedentary minutes and sleep could be a point of education for Bellabeat users. By promoting the benefits of less sedentary behavior and more activity, Bellabeat could potentially help users improve their sleep quality.
- Personalized Insights: The moderate relationship between steps and calories burned, as well as the stronger relationship between very active minutes and calories burned, could be used to provide personalized insights to users. For instance, Bellabeat could provide feedback on how a user's step count or activity level translates into calories burned. Bellabeat could also encourage their customers to increase their activity levels. This could be through targeted reminders or challenges within their app, encouraging users to hit a certain level of activity each day. This not only aligns with the company's goal of promoting a healthy lifestyle but also increases user engagement with their products.
- Wellness Education: Bellabeat could use these insights to educate their customers on wellness and health. For example, they could create blog posts or social media content about the impact of activity levels on calorie burn and sleep.
How could these trends help influence Bellabeat marketing strategy?
- Promotion of Active Lifestyle: Given the clear relationship between activity and calories burned, marketing campaigns can focus on promoting an active lifestyle. This can be achieved through success stories, tutorials for high-intensity workouts, or partnerships with fitness influencers.
- Targeted Reminders and Notifications: The information that people are most active between 5-7 pm can guide the timing of marketing communications. These hours could be optimal for pushing notifications about product features, wellness tips, or motivational messages to increase user engagement.
- Emphasis on Sleep Quality: Understanding the negative relationship between sedentary behavior and sleep duration, Bellabeat can market their sleep tracking features more effectively. They can provide information on how reducing sedentary behavior can lead to better sleep quality, thus attracting consumers interested in improving their sleep.
- Personalized Marketing: The data shows varying relationships between different types of activity and calories burned. Bellabeat can use this to target different segments of their customer base with personalized marketing messages. For example, they could target highly active users with features that track intense workouts and target less active users with features that help them increase their activity levels gradually.
- Educational Content: The trends and insights from the data can be used to create valuable educational content for consumers. This could include blog posts, infographics, or social media content about the benefits of being active, the impact of sedentary behavior on sleep, and how to make the most of their peak activity hours.
- Behavioral Change Campaigns: If Bellabeat finds that users are not meeting recommended guidelines for sleep or activity, they could run campaigns to encourage users to meet these goals. They could leverage their community features, like creating shared goals or challenges to increase motivation and engagement.
- Product Positioning: Knowing that users tend to have more very active minutes than fairly active ones, Bellabeat can position their products as tools for those who prefer high-intensity workouts. This could help differentiate Bellabeat products in the crowded wellness tech market.
Conclusion
In this project, we've delved into the world of fitness tracker data, leveraging the power of data analytics to uncover insights about smart device usage. As we analyzed the data, we discovered key trends that not only offer a glimpse into the behaviors and preferences of the typical fitness tracker user, but also provide actionable insights that Bellabeat can use to inform its marketing strategy and product development. From the preference for high-intensity activities to the link between sedentary behavior and sleep, these insights reveal potential opportunities for Bellabeat to better serve its customers, differentiate itself in the market, and ultimately drive its business growth.
- Smart Device Usage Trends: Data shows a preference for high-intensity activity, a moderate relationship between steps and calories burned, and peak activity hours between 5-7 pm. There's a weak negative correlation between sedentary behavior and sleep duration.
- Application to Bellabeat Customers: These trends suggest Bellabeat customers might benefit from features promoting high-intensity workouts, personalized insights based on their activity levels, and sleep improvement strategies.
- Influence on Bellabeat's Marketing Strategy: Insights can guide marketing campaigns promoting active lifestyles and better sleep, inform personalized and timely marketing communications, and help position Bellabeat's products for those preferring high-intensity workouts.
By applying the skills and techniques learned in the "Google Data Analytics Certification" to this real-world scenario, we've demonstrated the value of data analytics in driving informed decision-making, providing valuable insights, and ultimately contributing to business success.